When you need a piece of glue-code, a wrapper, or you want to execute a few commands in succession, Shell is the natural choice. However, Shell is almost never chosen for the implementation of larger applications. While there are some good reasons for that, there are also a number of good reasons in favor of shell.
In this series of posts, I am going to show the unexpected marvels that can be built with the shell (and Bash in particular), starting with a simple lock as the basis for increasingly complex IPC mechanisms used to build messaging-based distributed systems. Better yet, all of the code will be highly reusable, testable, and readable.
Why start with a lock?
When you have multiple processes accessing the same file, you need to make sure the file is not read from or written to at exactly the same time. Imagine you have the following code.
cnt=$(< counter)
((++cnt))
echo "$cnt" > counterIf you execute this code twice at exactly the same time, both
processes will read the same value from counter, increase it, and
write the same value (counter + 1) back to the file. As the result,
the counter will be increased by one, even though two processes
increased it. This is called a race condition, and locks such as
mutexes (mutex = mutual exclusion) solve race conditions by
making sure that resources are not accessed in parallel.
Making parallelism visible: petri nets
It’s not hard to imagine the possible states that a system with two processes and one lock can be in. But adding only one lock makes the system significantly more complicated, introducing problems such as deadlocks (two processes waiting for each other, bringing the system to a halt). That’s why I like to use petri nets to make the problem more tangible.
A petri net is a directed graph with places and transitions that shows the state of a system. Petri nets were invented to model chemical processes, but it turns out they are also a great tool to visualize parallelism.
In a nutshell:
- a circle is called a place and represents one or more lines of code without locking or unlocking operations
- a dot inside a place is called a token and shows that a place is currently being executed
- a box is called a transition and represents a lock or unlock operation
- there must be a place between two transitions and vice-versa
The code from earlier can be visualized like the following (for two instances).
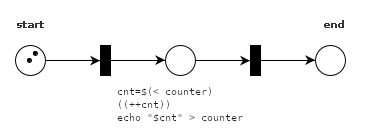
Petri nets show the state of a system over time, and change whenever one or more transitions fire. A transition fires when there is at least one token in each place that leads towards that transition. For example, these transitions can fire:
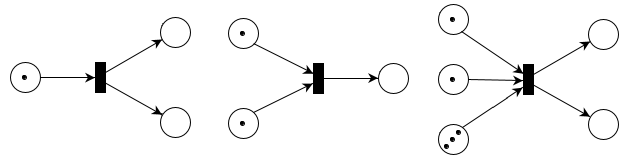
These transitions cannot fire:
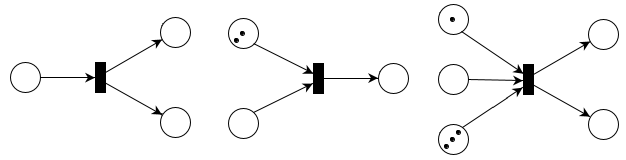
When a transition fires, it absorbs one token from each inbound connection and emits one token on each outbound connection. The number of absorbed and emitted tokens need not be the same. For example, a transition may emit two tokens even if it absorbs only one. This is how the three ready-to-fire petri nets above will change when the transitions fire.
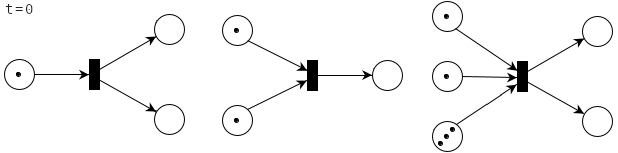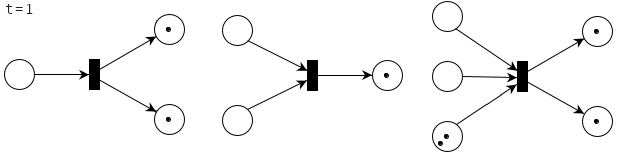
The petri net used to visualize the code from the top of this section might fire like this:

However, it might also fire like this:

If two transitions T0 and T1 are ready to fire, they might do so in any order, including at the same time. So the two tokens above might even proceed at exactly the same time, making the petri net reach its end state at t=2. This unpredictability of the order in which things are going to happen is what makes parallelism so hard.
Coming back to our mutex, what we need is a transition that makes sure only one thread of execution (that is, only one token) can proceed at a time. So what we need is a transition with an extra place that contains a token when we want to allow a token to pass (unlocked state), and does not contain a token when we don’t want any tokens to pass (locked state).
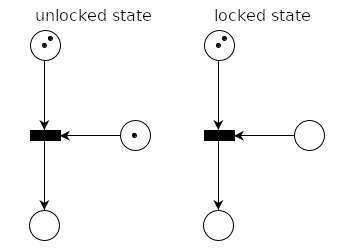
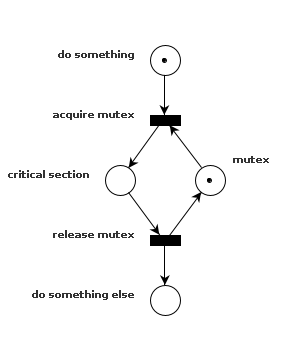
Because this transition needs one token from the top and one token from the right to fire, only one thread of execution will be able to proceed to the next place. The place that only one token can enter at a time is called critical section.
Now the mutex above isn’t very helpful if it can only be used once, so we add the unlock operation (and descriptions), where the token is returned to the mutex’s place.
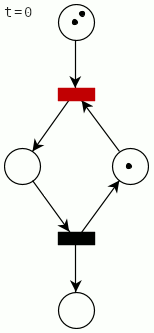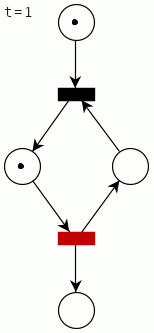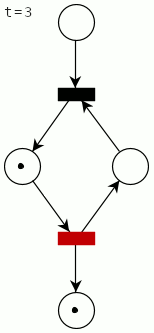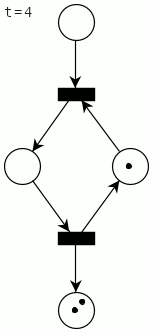
A complete cycle for the mutex with two processes looks like this (the firing transition is shown in red):
How (not) to implement a mutex
Now we know what a mutex looks like, but we still can’t implement one because we’re missing one crucial piece of information: the lock operation must be atomic. That means transitions must complete in a single step. To show why that’s important, let’s assume the lock operation is not atomic.
mutex_trylock() {
local lock="$1"
local locked
locked=$(< "$lock")
if (( locked == 0 )); then
echo "1" > "$lock"
return 0
fi
return 1
}Because the test whether the mutex is locked and the locking of the mutex are two separate steps, two processes executing the steps simultaneously will both see an unlocked mutex and lock it. We’re running into the very same problem why we needed the mutex in the first place. If the lock and unlock operation aren’t atomic, we will get a race condition accessing the mutex itself. So how do we do it atomically?
We need a way to test and set the lock in a single step. Or in other words,
if multiple processes execute the lock operation at exactly the same time,
the operation must fail for all but one process.
The POSIX standard gives us two commands that meet these criteria: the
first is ln (without -f!), the second is mkdir (without -p!). The ln command will
create a link and fail if the link already existed. For unlocking, we can
use rm - we don’t need to worry about atomicity here. The mkdir command
can be used in the same way, but I prefer ln because we can use the link
destination to store the process id of the process that created the link.
Locking
So what does our lock function look like? Thanks to the need for atomicity, it’s actually even simpler than the broken code above.
mutex_trylock() {
local lock="$1"
if ! ln -s "$BASHPID" "$lock"; then
return 1
fi
return 0
}Now there is one usability issue with this function: it will not wait until
the process has acquired the lock. However, this can be easily achieved by
wrapping it in a loop and adding a sleep to avoid busy-waiting.
mutex_lock() {
local lock="$1"
while ! mutex_trylock "$lock"; do
sleep 1
done
return 0
}Unlocking
The unlock operation does not need to be atomic, so we don’t need to be too
careful. However, to help us detect bugs, we would like to make sure that
only the process that locked the mutex can unlock it.
We use the process id stored in the symlink to figure out the owner (I’m
using $BASHPID because $$ does not give us the right process id when
executed in a subshell).
mutex_unlock() {
local lock="$1"
local owner
if ! owner=$(readlink "$lock"); then
# the mutex likely doesn't exist
return 1
fi
if (( owner != BASHPID )); then
# we're not the mutex's owner
return 2
fi
if ! rm "$lock"; then
# the permissions of the containing directory
# are likely preventing us from removing the mutex
return 3
fi
return 0
}A “thread”-safe counter
That’s everything we need to protect a shared resource from race conditions. Now
we can implement the counter from the introduction by putting the file access
between mutex_lock() and mutex_unlock() calls like so.
mutex_lock counter.mutex
cnt=$(< counter)
((++cnt))
echo "$cnt" > counter
mutex_unlock counter.mutexBecause mutex_lock() will put the process to sleep until the mutex was acquired,
we can be sure that the mutex is ours when the call returns. This seemingly makes
it very easy to avoid race conditions - and for small things like the counter above
it really is. But as already hinted above, once you start implementing things where
you need to acquire multiple mutexes at a time, things quickly become very
complicated. That’s when we will use petri nets to ensure that our implementations
are deadlock-free.
Keep your farewells and critical sections short
Another problem with mutexes is that, if one process has locked the mutex, all
other processes will be forced to wait until the mutex is unlocked. Therefore,
avoid doing things in your critical sections that might as well be done outside
of them. And absolutely avoid return or exit statements in critical sections.
You’re setting yourself up for disaster (and hours of debugging) if you have code
paths that leave locked mutexes behind.
When in doubt, petri nets are your friends. The next time, we will use them to model and implement semaphores, another primitive for synchronization.