I promised that we’re going to build a distributed system in bash, but the mutex that we’ve written in the last part is still pretty far way from that goal. This time, let’s build something more tangible: a queue!
Queues: Conveyor belts for data
A queue is a data structure for storing data in a first-in-first-out fashion. That means, when you take items from the queue, you get them in the same order that you put them into the queue. Exactly what we need for a message exchange. And the mutex from the last time will help us make the queues thread-safe1, so that multiple processes may put data into and take data from the queue at the same time without race conditions.
Let’s start with an naive approach. The queue has a list to store data items (one per line) and a counter that counts the data items in the queue. For thread-safety, both are protected by the same mutex. A producer will append data to the queue in four steps:
- Lock the mutex
- Append data to the list
- Increment the counter
- Unlock the mutex
Similarly, consumers will take data from the queue in these four steps:
- Lock the mutex
- If the counter is larger than 0
- take the first data item from the list, and
- decrement the counter
- Unlock the mutex
- If the counter was zero, go to step 1
This works, but there is a big problem (as you probably guessed, since I called this the naive approach). Imagine there is one consumer and no producer, and the function used to take a data item looks something like the following.
queue_get() {
local queue="$1"
local data
local -i count
for (( count = 0; count == 0; )); do
queue_lock "$queue"
count=$(queue_get_counter "$queue")
if (( count > 0 )); then
queue_dec_counter "$queue"
data=$(queue_take_head "$queue")
fi
queue_unlock "$queue"
done
echo "$data"
return 0
}Because there is nobody else locking the queue, the consumer will never wait
in queue_lock() and the loop becomes a tight loop, leaving one of your CPU
cores running at 100%. But this problem doesn’t just occur with only one
consumer. Even if you have more than one consumer. One consumer will always be
executing the loop (it may not always be the same one though), and you will
always have one CPU core running at full blast. Instead of wasting energy like
it’s 1970, let’s find a way to put consumers to sleep when there is nothing for
them to read.
An awful analogy: the semaphore
This is where another synchronization primitive enters the stage: the semaphore. In real life, a semaphore is a signal for trains. The kind that has an arm that moves up and down to signal whether the train may pass to the next track segment. The only thing that railroad semaphores and computing semaphores have in common is the name, so don’t make too much of it. While a normal mutex allows only one process at a time to proceed, a semaphore may allow multiple processes to proceed. Railroad semaphores don’t do that, at least not without making the evening news.
Instead, think of a semaphore as a thread-safe counter with two atomic operations:
- post: Increase the counter
- wait: Wait until the counter is greater than 0, then decrease it
This is what the petri net for a semaphore looks like:
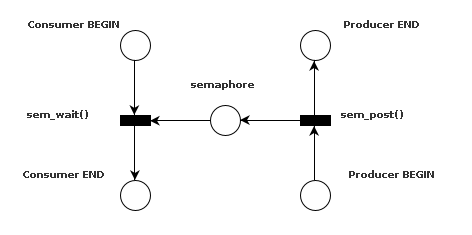
The consumer, starting at the top left, will not be able to proceed until
a token has been added to the semaphore. Tokens are added by the producer
using sem_post() (the reason I drew the producer upside-down is that the
petri net for the queue is symmetrical if you draw it this way).
Putting things together
How does that help us with our queue? Instead of storing the number of data items in a counter, we will use a semaphore as counter.
The entire queue ends up looking something like the following.
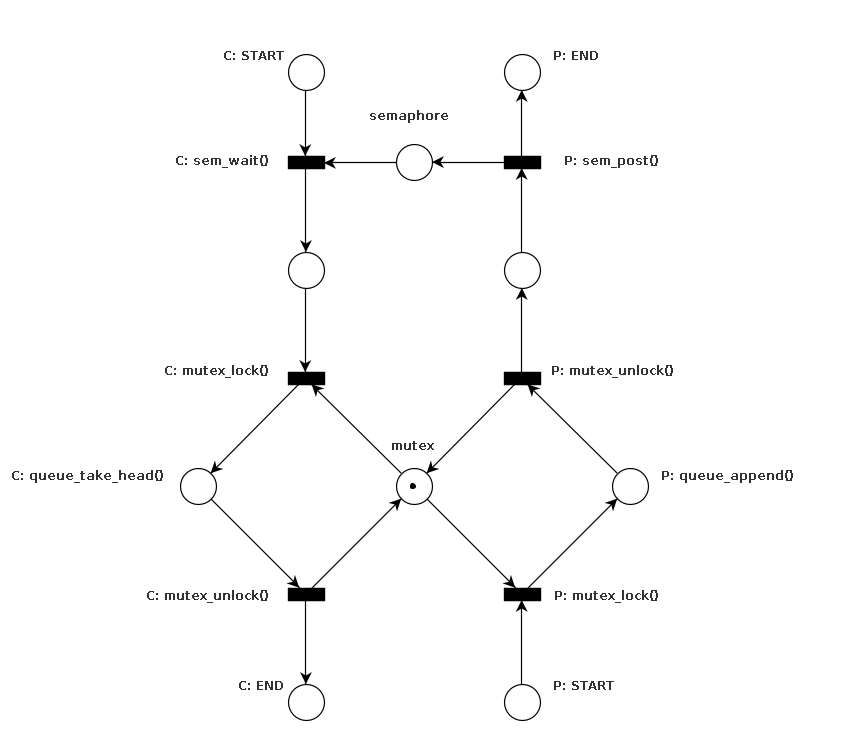
Places prefixed with C belong to the consumer (i.e.queue_get()), places
prefixed with P belong to the producer (i.e.queue_put()). I have left the
two places between the semaphore and the mutex unlabelled because neither the
consumer nor the producer will execute anything in those places. Nevertheless,
they might be interrupted between the semaphore and mutex operations, so the
state is necessary (also, it’s not allowed to directly connect two transitions).
Getting data from the queue: queue_get()
Thanks to the semaphore, we can write queue_get() without of any loops! Okay,
you might argue that’s because the looping happens in sem_wait() now, but let’s
not split hairs2. I also added some error checking, because no code is
complete without error checking.
queue_get() {
local queue="$1"
local sem
local mutex
local data
local err
err=0
sem=$(queue_get_semaphore "$queue")
mutex=$(queue_get_mutex "$queue")
sem_wait "$sem"
mutex_lock "$mutex"
if ! data=$(queue_take_head "$queue"); then
err=1
fi
mutex_unlock "$mutex"
if (( err == 0 )); then
echo "$data"
fi
return "$err"
}Because sem_wait() suspends the caller until the counter is larger than 0, and
because it will let only as many processes proceed as there are data items in the
queue, we don’t have to check any counters. All we have to do is lock the mutex to
make sure we don’t read from the queue at the same time as any of the other processes
that were let through the semaphore.
Putting data in the queue: queue_put()
Earlier, I pointed out the symmetry of the queue’s petri net. That was not just for
aesthetic purposes (that’s not to say aesthetics aren’t important), but it tells us
something important about the two functions. First, neither of them have any loops
or branches (but we know that already). Second, we can tell that queue_put() has
to call mutex_lock(), mutex_unlock(), and sem_post(), in this order. This is
what it looks like:
queue_put() {
local queue="$1"
local data="$2"
local sem
local mutex
local err
err=0
sem=$(queue_get_semaphore "$queue")
mutex=$(queue_get_mutex "$queue")
mutex_lock "$mutex"
if ! queue_append "$queue" "$data"; then
err=1
fi
mutex_unlock "$mutex"
sem_post "$sem"
return "$err"
}Fun fact: The shell has structs
At this point you are hopefully wondering about the value of the queue argument that
is passed to the functions. If this were C, the queue argument would be something
like struct queue *queue, but since the shell does not have a notion of structs, and
because shell variables can’t be shared between processes, we have to use something that
we can share with other processes: file system objects.
A struct in C is a type that contains other types; a file system object that can contain
other file system objects is a directory. Therefore, the queue argument contains the
shell equivalent of a pointer to a struct: the path to a directory.
queue_get_semaphore() and queue_get_mutex()
This also answers the question, what exactly the queue_get_semaphore() and
queue_get_mutex() functions do. They return the path of the semaphore and mutex
that is contained within $queue. Depending on your coding style they could be
one-liners or you could omit them completely, but I encourage you to write them
something like the following because it’s more readable and less work if you
decide you want to change the name of any of the queue’s members.
queue_get_semaphore() {
local queue="$1"
echo "$queue/sem"
return 0
}
queue_get_mutex() {
local queue="$1"
echo "$queue/mutex"
return 0
}queue_init() and queue_destroy()
Now that we know what’s behind these two functions, we can also write functions
that initialize and clean up a queue. The initialization function, queue_init()
simply attempts to create a new directory with a semaphore inside.
queue_init() {
local queue="$1"
local sem
sem=$(queue_get_semaphore "$queue")
if ! mkdir "$queue"; then
# queue exists
return 1
fi
if ! sem_init "$sem"; then
if ! rmdir "$queue"; then
echo "Could not clean up $queue" 1>&2
fi
return 1
fi
return 0
}Likewise, the destructor queue_destroy() attempts to free the queue’s semaphore
and then removes the entire queue.
queue_destroy() {
local queue="$1"
local sem
sem=$(queue_get_semaphore "$queue")
if ! sem_destroy "$sem"; then
return 1
fi
if ! rm -rf "$queue"; then
return 1
fi
return 0
}You might argue that the sem_destroy() call is not necessary since the semaphore
would be removed by rm -rf anyways, but the call serves another purpose: to make
sure that $queue actually points to a valid queue (or a directory that contains
a semaphore anyways).
It’s not perfect, but it will protect you from havoc in case you accidentally pass
your home directory or some other location you probably don’t intend to part with
just yet.
queue_append() and queue_take_head()
The last missing piece in our queue implementation are the two functions that add
data to and remove data from the queue. In our implementation, we will create a
file called data inside the queue directory and add the data items to this file,
one item per line. This way, we can easily access the first item using head and
append items to the file using the >> operator.
queue_get_data() {
local queue="$1"
echo "$queue/data"
return 0
}
queue_take_head() {
local queue="$1"
local data
local first
data=$(queue_get_data "$queue")
if ! first=$(head -n 1 "$data"); then
return 1
elif ! sed -i '1d' "$data"; then
return 1
fi
echo "$first"
return 0
}The queue_take_head() function attempts to read the first item from the queue file
and, if successful, removes the first line from the queue file. The queue_append()
function is even more simple, doing nothing but appending a line.
queue_append() {
local queue="$1"
local item="$2"
local data
data=$(queue_get_data "$queue")
if ! echo "$item" >> "$data"; then
return 1
fi
return 0
}There is one problem with the above two functions though. Like many things in the shell world, they can’t handle line breaks, so we have to do what we always to when we want to prevent the shell from mangling our data: encode it in base643. The functions need to be tweaked only slightly:
queue_append() {
local queue="$1"
local item="$2"
local data
local encoded
data=$(queue_get_data "$queue")
if ! encoded=$(base64 -w 0 <<< "$item"); then
return 1
fi
if ! echo "$encoded" >> "$data"; then
return 1
fi
return 0
}Note the -w 0 argument passed to base64. If you forget this (like I did when I first
wrote this function), base64 will insert newlines every 76 bytes of output. D’oh!
queue_take_head() {
local queue="$1"
local data
local first
data=$(queue_get_data "$queue")
if ! first=$(head -n 1 "$data"); then
return 1
elif ! sed -i '1d' "$data"; then
return 1
elif ! base64 -d <<< "$first"; then
return 1
fi
return 0
}The improved queue_take_head() function is even simpler: only the last echo
needs to be replaced with base64. However, since base64 may return an error,
we need to make sure to handle that.
The complete picture
The complete queue implementation looks like this.
queue_init() {
local queue="$1"
local sem
sem=$(queue_get_semaphore "$queue")
if ! mkdir "$queue"; then
# queue exists
return 1
fi
if ! sem_init "$sem"; then
if ! rmdir "$queue"; then
echo "Could not clean up $queue" 1>&2
fi
return 1
fi
return 0
}
queue_destroy() {
local queue="$1"
local sem
sem=$(queue_get_semaphore "$queue")
if ! sem_destroy "$sem"; then
return 1
fi
if ! rm -rf "$queue"; then
return 1
fi
return 0
}
queue_get() {
local queue="$1"
local sem
local mutex
local data
local err
err=0
sem=$(queue_get_semaphore "$queue")
mutex=$(queue_get_mutex "$queue")
sem_wait "$sem"
mutex_lock "$mutex"
if ! data=$(queue_take_head "$queue"); then
err=1
fi
mutex_unlock "$mutex"
if (( err == 0 )); then
echo "$data"
fi
return "$err"
}
queue_put() {
local queue="$1"
local data="$2"
local sem
local mutex
local err
err=0
sem=$(queue_get_semaphore "$queue")
mutex=$(queue_get_mutex "$queue")
mutex_lock "$mutex"
if ! queue_append "$queue" "$data"; then
err=1
fi
mutex_unlock "$mutex"
sem_post "$sem"
return "$err"
}
queue_get_semaphore() {
local queue="$1"
echo "$queue/sem"
return 0
}
queue_get_mutex() {
local queue="$1"
echo "$queue/mutex"
return 0
}
queue_get_data() {
local queue="$1"
echo "$queue/data"
return 0
}
queue_take_head() {
local queue="$1"
local data
local first
data=$(queue_get_data "$queue")
if ! first=$(head -n 1 "$data"); then
return 1
elif ! sed -i '1d' "$data"; then
return 1
elif ! base64 -d <<< "$first"; then
return 1
fi
return 0
}
queue_append() {
local queue="$1"
local item="$2"
local data
local encoded
data=$(queue_get_data "$queue")
if ! encoded=$(base64 -w 0 <<< "$item"); then
return 1
fi
if ! echo "$encoded" >> "$data"; then
return 1
fi
return 0
}But what about …?
“That’s nice,” you might think, “but it doesn’t really work without the semaphore functions.” You’re completely right. I meant to explain about semaphores in this post, but it turned out to be a bit longer than I expected, so I’ll leave that for the next time. :-)
Footnotes
-
I should be using the term process-safe, since we the shell doesn’t have threads, but I feel that would cause confusion. Please ignore the inaccuracy. ↩
-
Actually, moving loops into separate functions is a very easy way to make your code more readable. ↩
-
This way you can also store binary data in shell variables. ↩